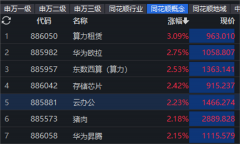
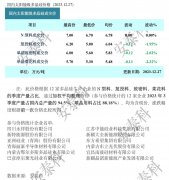
时间:2024-04-30 14:05来源:[db:来源]作者:[db:作者]点击:


(原标题:深度|中国大模型追星赶月的这一年:变化、趋势与展望!)
如果要评选今年最热的科技风口与最火的投资赛道,或许没有一个人会忽略人工智能大模型。
与以往任何一场颠覆性的技术革新相比,大模型的浪潮来得更为迅猛和狂热。去年11月,美国硅谷的OpenAI公司发布ChatGPT后,大模型的潮水就越过广袤的太平洋,席卷国内科技圈和投资圈,并在极短的时间内让大家达成了共识——没有犹豫,没有怀疑,几乎所有科技公司都在押注大模型。
2023年被视为中国大模型的发展元年。在中国大模型追星赶月的这一年,技术迭代日新月异,行业趋势不断变化,一切的发生都来得更快,也更超乎我们的想象。尽管未来总是难以预测,但我们可以复盘过去一年里的风起与浪涌,通过潮水的走向,展望大模型的前进方向。
从集体焦虑到奋起直追
“年初大家看到ChatGPT已经实现了智能涌现、有了数据飞轮,国内整体处于比较慌乱的状态,感觉面临着整体掉队的情况。”在今年11月中旬的一场人工智能主题论坛上,大模型创业公司百川智能的创始人王小川说。
焦虑是年初弥漫在国内科技圈的一种集体情绪。但很快,各大科技巨头、科研院所、初创公司都纷纷下场,部署自己的大模型。科技行业资深投资人庄明浩在接受证券时报记者采访时表示,移动互联网时代的创业者最初还会迟疑,很多厂商没有马上跟进,但在飞速进化的大模型面前,人们没有时间犹豫。“今年春节以后,大家就达成了统一的共识,开始搭建团队、买卡,动手做大模型。”庄明浩表示。
3月16日,百度正式推出了基于百度新一代大语言模型的生成式AI产品“文心一言”,成为了率先“跑出来”的国内大模型厂商。文心一言的问世,也拉开了国内“百模大战”的帷幕。此后,阿里、华为、腾讯、京东、科大讯飞、360、字节跳动等科技公司纷纷发布了自家的大模型。
同台竞技的玩家,还有科研院所及创业公司。北京智源人工智能研究院发布了“悟道”大模型,上海人工智能实验室推出了“书生”大模型,鹏城实验室研发了“鹏城·脑海”大模型。王小川创立的百川智能、清华计算机系孵化的智谱AI等初创公司如冉冉新星,以卓越的自研能力备受行业关注。
文心一言发布8个月后的11月15日,李彦宏在深圳西丽湖论坛上表示,国内目前已经发布了238个大模型。这意味着,在这两百多天里,平均每天都有一个大模型问世。“在过去的一年中,中国大模型的规模呈现快速增长的趋势。许多企业和研究机构投入大量资源,开发出拥有数十亿、甚至百亿级别参数的大模型,这些模型在多个自然语言处理任务上取得了显著的性能提升。”北京市社会科学院管理研究所副研究员王鹏在接受记者采访时说。
王鹏进一步表示,大模型数量迅速增长的同时,技术创新也在不断涌现。例如,针对大模型训练过程中的效率问题,研究人员提出了多种优化算法和并行计算技术,显著提高了训练速度和效率。同时,针对大模型的推理速度问题,也有一系列轻量级大模型和模型压缩技术的出现。
奋起直追的这一年,努力对标ChatGPT的中国大模型厂商们已经走出了集体焦虑。王小川在论坛中表示,“如今已比年初时好多了”,并预计国内大模型在明年有机会追赶上ChatGPT 4的水平。不过,ChatGPT自身也在不断进化的过程中,追赶之路或许还将持续。
从“卷”基础大模型到“卷”落地应用
当几百个大模型集体涌现,一个问题开始萦绕在人们心头:中国需要那么多大模型吗?
庄明浩向记者分析,一家公司如果想做大模型,至少应该回答四个问题:
一是算力,是否有足够多的钱和渠道买到足够多的高性能显卡;
二是团队,是否能招到有大模型实施经验的高质量团队;
三是工程,是否有相对快的路径训练大模型;
四是监管,大模型做出来以后能否通过备案。
由于创业门槛高,务实的中国大模型创业者很快就意识到,基础大模型未来可能是少数几家寡头的游戏,更多的机会蕴藏在应用层当中。红杉美国在关于大模型的报告中指出,在大模型的首年,“第一幕”是从技术出发,发现了基础大模型这个新的“锤子”,目前市场正在进入“第二幕”,将端到端地解决人类问题。“我们需要拿着锤子找钉子。”庄明浩说。
这个“钉子”,就是具体的场景和应用,不少创业公司已经在今年找到了一些“钉子”,并快速挣到了钱。“我们看到很多小团队做出各种各样接地气的应用,比如说帮品牌生成商拍图、用数字人做弹幕游戏直播等等,有不少AI项目从第一天就开始收费赚钱了。”专注于AI投资的锦秋基金执行董事臧天宇在接受记者采访时表示。他认为,模型层的机会正在收敛,而应用层的想象空间正在打开,产品价值开始凸显。
事实上,正是基础大模型的发展为应用层的繁荣提供了必要的条件,也让聚焦于垂直应用的AI创业公司的成本大大降低。今年2月,Meta公司开源了高质量的LLaMA基础语言模型;而早在去年8月,Stability AI公司就开源了Stable Diffusion图像生成模型。这意味着,创业公司不必自己投入大量资源训练模型,可以在这些开源大模型的基础之上,利用自己积累的行业数据进行微调,从而形成满足特定任务的应用。
今年7月,一款名为“秒鸭相机”的小程序在社交网络火出圈,成为国内首个AIGC(生成式人工智能)爆款应用。用户只需支付9.9元,上传一些照片,就可以生成不同系列的、质感堪比照相馆拍出来的照片。不仅是创业公司,科技大厂也都开始向金融、医疗、交通、教育等各个行业进军,加快商业落地步伐,“赋能千行百业”成为大模型厂商共同的追求。
业内的一个共识是,中国在基础大模型方面不具有显著优势,但可以在应用层方面另辟蹊径。王鹏向记者分析,中国拥有庞大的市场和用户基础,更容易获取大量的用户数据和应用场景,能为大模型的应用提供丰富的数据资源。同时,多样化的场景也为大模型应用提供了广阔的空间,例如在智能客服、智能推荐、智能翻译等领域,中国大模型已经取得了显著的成果。
从投融资火热到资金趋于冷静
大模型引发的创业热潮,直接体现在投融资上。IT桔子近期发布的一份报告显示,虽然2023年投融资整体行业遇冷,但总体而言,AI行业融资的形势相对仍处于比较热门的状态。截至今年11月20日,人工智能赛道在一级市场的总融资事件为530起,总融资交易额估算有631亿元。
不过,虽然大模型从年初火热到年底,但接受记者采访的多名业内人士均表示,投资人从下半年开始就“看得多投得少”。“今年上半年,大家基本就把创业公司的几个种子选手筛选出来投完了。这几家公司是大家公认在人员、算法、算力、数据等维度上比较有竞争优势的公司,在很短的时间内估值就达到了很高的水平。其他公司拿到钱的很少,投融资情况与媒体报道的热度相比要冷得多。”庄明浩告诉记者。
大模型投融资领域,马太效应正在显现,极少数的玩家得到了绝大多数资本的青睐。根据IT桔子的报告,2023年新晋人工智能领域独角兽有10家,其中AIGC及大模型相关的有4家,分别是智谱AI、百川智能、Minimax和零一万物。其中,前三家公司年内融资金额分别达到25亿元、数亿美元和超2.5亿美元,均排在2023年人工智能领域融资总额最多的中国公司前十名。艾瑞咨询最近发布的报告显示,在获投的应用与模型层创业项目中,获投3次及以上的公司占17%,这反映了AIGC创业前期需要大量资金支持,也说明优质项目仍非常稀缺。
对于小规模的大模型初创公司而言,找到竞争壁垒与“护城河”是成功融资的关键,但这并非易事。庄明浩表示,很多初创公司转向了“小作坊做小工具”的模式,先找准一个市场上还没有的功能与产品,抓住窗口期,通过运营手段快速推广,哪怕这个窗口期只有3到6个月,也可以挣到一笔钱,而后继续寻找新的市场机会。
还是以妙鸭相机举例,这一产品刚推出便受到了市场的追捧,从第一天便开始收费,但市场的热度也很快就降了下来。这与移动互联网时代的应用早期通过免费争夺用户市场,而后再逐步开始收费的创业模式已经完全不同。
展望:多模态引领下个浪潮,产业化商业化持续加速
根据工信部赛迪研究院最新数据,今年我国语言大模型市场规模实现较快提升,应用场景不断丰富。预计今年我国语言大模型市场规模将达到132.3亿元,增长率将达110%。
2023年,中国大模型从整体而言是语言大模型的天下。然而,与年初所有人的注意力都在ChatGPT上相比,如今行业的关注点开始向多模态方向转移。尤其是年末,文生视频应用Pika的爆火以及谷歌发布多模态大模型Gemini,更是打开了市场对跨模态、多模态的想象空间。
多模态大模型是结合文本、图像、音频等多种模态信息进行学习和理解的人工智能模型。人工智能发展的进化方向是变得“更像人”,这决定了大模型不能停留在单一模态,需要像人类一样能够理解和处理不同模态的信息。“随着计算机视觉、语音识别等技术的不断发展,跨模态大模型逐渐成为研究热点。多模态信息的融合和交互,为人工智能应用提供了更加丰富的可能性。”王鹏表示。
锦秋基金投资副总裁郑晓超表示,在不同模态的大模型中,目前文本与图像已进入到相对成熟并且应用开始爆发的阶段,但3D、音频、视频则仍处于技术发展早期。庄明浩告诉记者,以上几个领域还没有达到“ChatGPT时刻”,技术路线尚未统一,未来创业者会在这些领域广泛尝试。
随着多模态技术的不断迭代进步,大模型将在具身智能、自动驾驶等领域开拓新的应用场景。与此同时,加快产业化落地和商业化加速,依然是行业的高度共识。昆仑万维董事长兼CEO方汉在不久前的一场会议中公开表示,今年AIGC爆火主要是技术推动,核心是技术转化成产品和市场,真正的商业模式创新会是下一代巨头成长的底层基因。臧天宇认为,越来越多的细分行业和场景在拥抱AI,未来3—5年会诞生一套成熟的AI产品方法论,更多有商业价值的应用会被创造出来,实现千亿乃至万亿级的AI应用市场机会。
2023年作为中国大模型的元年,也是监管启动的一年。在大模型狂飙突进的发展过程中,数据安全、隐私保护、伦理道德、知识产权等挑战日益显现,大模型自身的可解释性与“幻觉”问题也亟待解决,相关的监管政策已经陆续出台。7月,网信办等七部门发布了《生成式人工智能服务暂行管理办法》,坚持发展和安全并重、促进创新和依法治理相结合的原则,采取有效措施鼓励生成式人工智能创新发展。
“中国大模型要实现更好发展,除了要解决智能算力短板、克服数据质量和多样性方面的难题、加快技术创新以外,还需要应对隐私和安全、伦理和法规等方面的挑战,确保人工智能技术的发展符合社会伦理和法律法规的要求。”王鹏表示。
责编:朱雨蒙
校对:祝甜婷